Moroccan License Plate Detection and Recognition
Overview
This project detects and recognizes Moroccan vehicle license plates using the YOLOv3 model and Optical Character Recognition (OCR). The implementation is done in Python using OpenCV for image processing and Pytesseract for OCR. The system identifies license plates and interprets the characters, including Arabic letters and numbers.
Technologies Used
- YOLOv3: Used for object detection to identify the license plates in images.
- OpenCV: Utilized for image processing and drawing bounding boxes around detected plates.
- Pytesseract: An OCR tool for extracting text from images.
- Arabic_reshaper and python-bidi: Libraries for handling and displaying Arabic text correctly.
Objective
The goal of this project is to provide an efficient and accurate method for detecting and recognizing Moroccan license plates from images. This can be used in various applications such as traffic monitoring, parking management, and security systems.
Project Structure
Import Necessary Libraries
import cv2
import pytesseract
import numpy as np
import arabic_reshaper
from bidi.algorithm import get_display
from PIL import Image
import matplotlib.pyplot as plt
These libraries are essential for handling images, performing OCR, and reshaping Arabic text for correct display.
Define Enumerations and Classes
Utility Function to Create Enumerations
def enum(*sequential, **named):
enums = dict(zip(sequential, range(len(sequential))), **named)
return type('Enum', (), enums)
# Define OCR_MODES enumeration
OCR_MODES = enum('TRAINED', 'TESSERACT')
The utility function creates an enumeration to define OCR modes: TRAINED for the YOLOv3 OCR model and TESSERACT for Tesseract OCR.
PlateDetector Class
The PlateDetector class is responsible for detecting license plates in images.
Load Model
def load_model(self, weight_path: str, cfg_path: str):
self.net = cv2.dnn.readNetFromDarknet(cfg_path, weight_path)
with open("classes-detection.names", "r") as f:
self.classes = [line.strip() for line in f.readlines()]
self.layers_names = self.net.getLayerNames()
unconnected_out_layers = self.net.getUnconnectedOutLayers().flatten()
self.output_layers = [self.layers_names[i - 1] for i in unconnected_out_layers]
- Loads the YOLOv3 detection model using specified weight and configuration files.
- Reads the class names for detection from
classes-detection.names.
Load Image
def load_image(self, img_path):
img = cv2.imread(img_path)
height, width, channels = img.shape
return img, height, width, channels
- Loads an image from the specified path and returns its dimensions.
Detect Plates
def detect_plates(self, img):
blob = cv2.dnn.blobFromImage(img, scalefactor=0.00392, size=(320, 320), mean=(0, 0, 0), swapRB=True, crop=False)
self.net.setInput(blob)
outputs = self.net.forward(self.output_layers)
return blob, outputs
- Converts the image into a blob and runs the YOLOv3 detection model to detect license plates.
Get Boxes
def get_boxes(self, outputs, width, height, threshold=0.3):
boxes = []
confidences = []
class_ids = []
for output in outputs:
for detection in output:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > threshold:
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
return boxes, confidences, class_ids
- Extracts bounding boxes, confidences, and class IDs for detected objects based on a confidence threshold.
Draw Labels
def draw_labels(self, boxes, confidences, class_ids, img):
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.1, 0.1)
font = cv2.FONT_HERSHEY_PLAIN
plats = []
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
label = str(self.classes[class_ids[i]])
color_green = (0, 255, 0)
crop_img = img[y:y + h, x:x + w]
try:
crop_resized = cv2.resize(crop_img, dsize=(470, 110))
plats.append(crop_resized)
cv2.rectangle(img, (x, y), (x + w, y + h), color_green, 8)
confidence = round(confidences[i], 3) * 100
cv2.putText(img, str(confidence) + "%", (x + 20, y - 20), font, 2, (0, 255, 0), 2)
except cv2.error as err:
print(err)
return img, plats
- Draws bounding boxes around detected plates on the image and crops the detected plate regions.
PlateReader Class
The PlateReader class is responsible for reading the text from the detected license plates.
Load Model
def load_model(self, weight_path: str, cfg_path: str):
self.net = cv2.dnn.readNetFromDarknet(cfg_path, weight_path)
with open("classes-ocr.names", "r") as f:
self.classes = [line.strip() for line in f.readlines()]
self.layers_names = self.net.getLayerNames()
unconnected_out_layers = self.net.getUnconnectedOutLayers().flatten()
self.output_layers = [self.layers_names[i - 1] for i in unconnected_out_layers]
self.colors = np.random.uniform(0, 255, size=(len(self.classes), 3))
- Loads the YOLOv3 OCR model using specified weight and configuration files.
- Reads the class names for OCR from
classes-ocr.names.
Load Image
def load_image(self, img_path):
img = cv2.imread(img_path)
height, width, channels = img.shape
return img, height, width, channels
- Loads an image from the specified path and returns its dimensions.
Read Plate
def read_plate(self, img):
blob = cv2.dnn.blobFromImage(img, scalefactor=0.00392, size=(320, 320), mean=(0, 0, 0), swapRB=True, crop=False)
self.net.setInput(blob)
outputs = self.net.forward(self.output_layers)
return blob, outputs
- Converts the image into a blob and runs the YOLOv3 OCR model to recognize characters on the plate.
Get Boxes
def get_boxes(self, outputs, width, height, threshold=0.3):
boxes = []
confidences = []
class_ids = []
for output in outputs:
for detect in output:
scores = detect[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > threshold:
center_x = int(detect[0] * width)
center_y = int(detect[1] * height)
w = int(detect[2] * width)
h = int(detect[3] * height)
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
return boxes, confidences, class_ids
- Extracts bounding boxes, confidences, and class IDs for detected characters based on a confidence threshold.
Draw Labels
def draw_labels(self, boxes, confidences, class_ids, img):
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.1, 0.1)
font = cv2.FONT_HERSHEY_PLAIN
c = 0
characters = []
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
label = str(self.classes[class_ids[i]])
color = self.colors[i % len(self.colors)]
cv2.rectangle(img, (x, y), (x + w, y + h), color, 3)
confidence = round(confidences[i], 3) * 100
cv2.putText(img, str(confidence) + "%", (x, y - 6), font, 1, color, 2)
characters.append((label, x))
characters.sort(key=lambda x: x[1])
plate = ""
for l in characters:
plate
+= l[0]
chg = 0
for i in range(len(plate)):
if plate[i] in ['b', 'h', 'd', 'a']:
if plate[i - 1] == 'w':
ar = i - 1
chg = 2
elif plate[i - 1] == 'c':
ar = i - 1
chg = 3
else:
ar = i
chg = 1
if chg == 1:
plate = plate[:ar] + ' | ' + str(self.arabic_chars(ord(plate[ar])), encoding="utf-8") + ' | ' + plate[ar + 1:]
if chg == 2:
index = sum(ord(plate[ar + j]) for j in range(3))
plate = plate[:ar] + ' | ' + str(self.arabic_chars(index), encoding="utf-8") + ' | ' + plate[ar + 3:]
if chg == 3:
index = sum(ord(plate[ar + j]) for j in range(2))
plate = plate[:ar] + ' | ' + str(self.arabic_chars(index), encoding="utf-8") + ' | ' + plate[ar + 2:]
return img, plate
- Draws bounding boxes around detected characters and builds the final plate text.
- Handles conversion of Latin characters to corresponding Arabic characters.
Arabic Character Conversion
def arabic_chars(self, index):
if index == ord('a'):
return "أ".encode("utf-8")
if index == ord('b'):
return "ب".encode("utf-8")
if index == 2 * ord('w') + ord('a') or index == ord('w'):
return "و".encode("utf-8")
if index == ord('d'):
return "د".encode("utf-8")
if index == ord('h'):
return "ه".encode("utf-8")
if index == ord('c') + ord('h'):
return "ش".encode("utf-8")
- Converts detected Latin characters to Arabic letters for correct representation.
Tesseract OCR
def tesseract_ocr(self, image_path, lang="eng", psm=7):
alphanumeric = "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
options = f"-l {lang} --psm {psm} -c tessedit_char_whitelist={alphanumeric}"
return pytesseract.image_to_string(image_path, config=options)
- Uses Tesseract OCR to recognize alphanumeric characters from images, with specified language and page segmentation mode.
Process Image Function
def process_image(image_path, ocr_mode=OCR_MODES.TRAINED):
image, height, width, channels = detector.load_image(image_path)
blob, outputs = detector.detect_plates(image)
boxes, confidences, class_ids = detector.get_boxes(outputs, width, height, threshold=0.3)
plate_img, LpImg = detector.draw_labels(boxes, confidences, class_ids, image)
if len(LpImg):
cv2.imwrite("tmp/car_box.jpg", plate_img)
cv2.imwrite('tmp/plate_box.jpg', LpImg[0])
display_image('tmp/car_box.jpg', 'Detected Plates')
display_image('tmp/plate_box.jpg', 'Detected Plate')
if ocr_mode == OCR_MODES.TRAINED:
return apply_trained_ocr('tmp/plate_box.jpg')
elif ocr_mode == OCR_MODES.TESSERACT:
return reader.tesseract_ocr('tmp/plate_box.jpg')
else:
print("No license plate detected.")
return None
- Processes an input image to detect and recognize license plates.
- Saves the detected plates and displays them for verification.
- Returns the recognized plate text based on the selected OCR mode.
Apply Trained OCR Function
def apply_trained_ocr(plate_path):
image, height, width, channels = reader.load_image(plate_path)
blob, outputs = reader.read_plate(image)
boxes, confidences, class_ids = reader.get_boxes(outputs, width, height, threshold=0.3)
segmented, plate_text = reader.draw_labels(boxes, confidences, class_ids, image)
cv2.imwrite("tmp/plate_segmented.jpg", segmented)
display_image("tmp/plate_segmented.jpg", 'Segmented Plate')
return arabic_reshaper.reshape(plate_text)
- Applies the trained OCR model to recognize and segment characters on the detected license plate.
- Returns the reshaped Arabic text.
Example Usage
image_path = input("Enter the path of the image: ")
ocr_mode = input("Enter OCR mode (trained/tesseract): ").strip().lower()
if ocr_mode == "trained":
ocr_mode = OCR_MODES.TRAINED
else:
ocr_mode = OCR_MODES.TESSERACT
result = process_image(image_path, ocr_mode)
print("Detected Plate Text:", result)
- Prompts the user to input the path of the image and the desired OCR mode.
- Processes the image and prints the detected plate text.
Outputs
- Image Outputs: The system saves and displays images with detected plates and segmented plate characters.
- Plate Text: The text extracted from the license plate, showing the numbers and letters, including Arabic characters.
Enter the path of the image: ./license_plate_detection/MLPDR/test_images/porshe.png
Enter OCR mode (trained/tesseract): trained


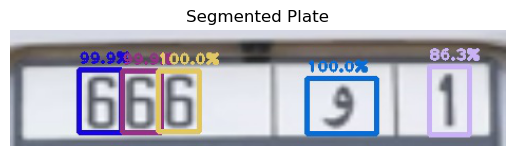
Detected Plate Text: 666 | ﻭ | 1
Streamlit Web Interface
To make the model more accessible and user-friendly, I developed a Streamlit web interface that allows users to interact with the license plate detection system through a simple web browser.
Features
- Drag-and-drop image upload
- Real-time license plate detection and recognition
- Visual display of detection steps:
- Original image
- Detected license plate
- Segmented characters
- Final recognition results
- Option to switch between OCR modes (Trained model vs Tesseract)
Interface Screenshots
 Main interface with image upload area
Main interface with image upload area
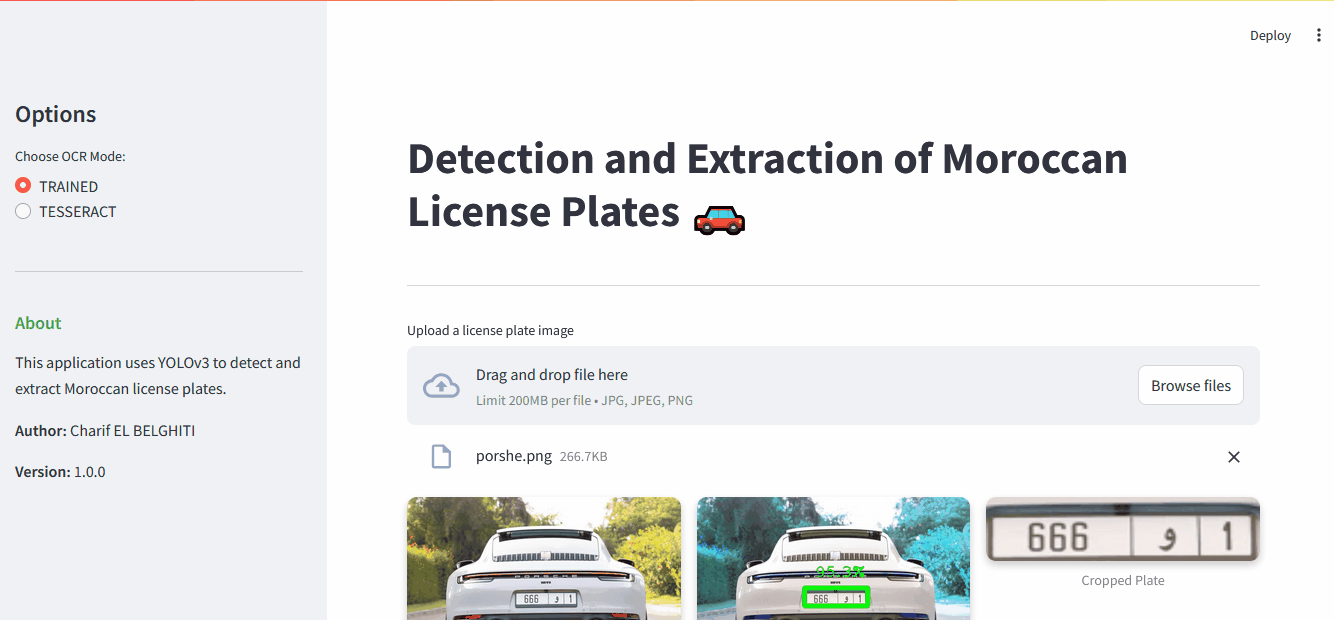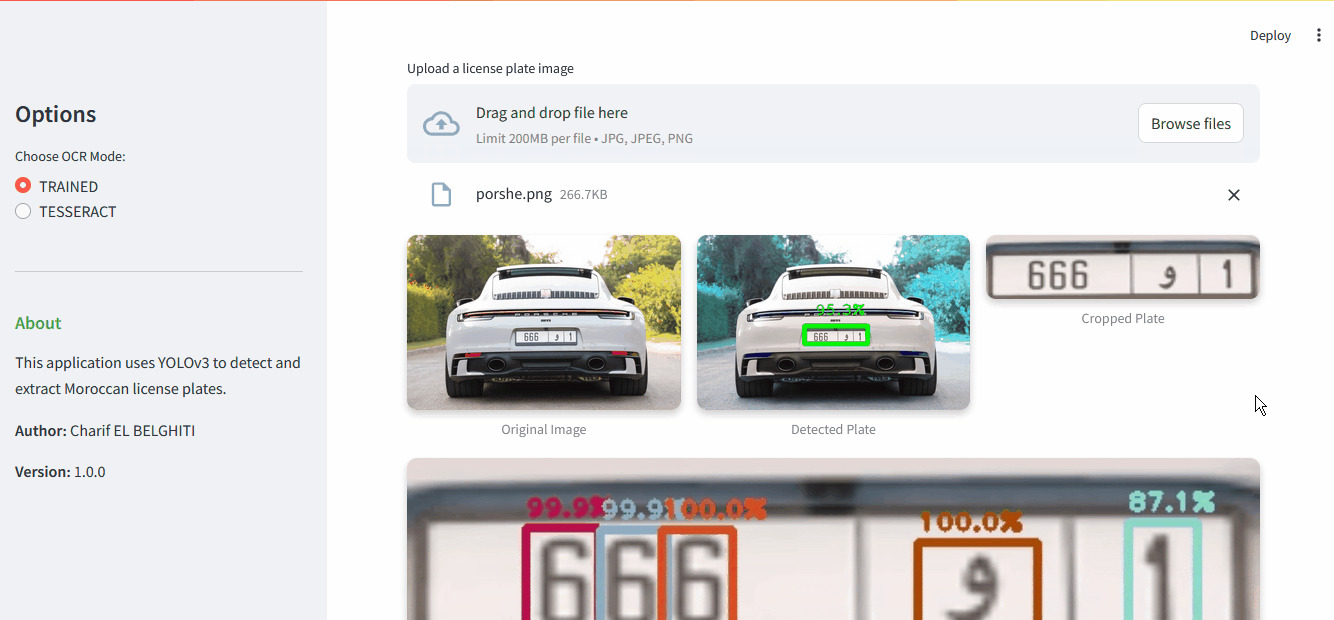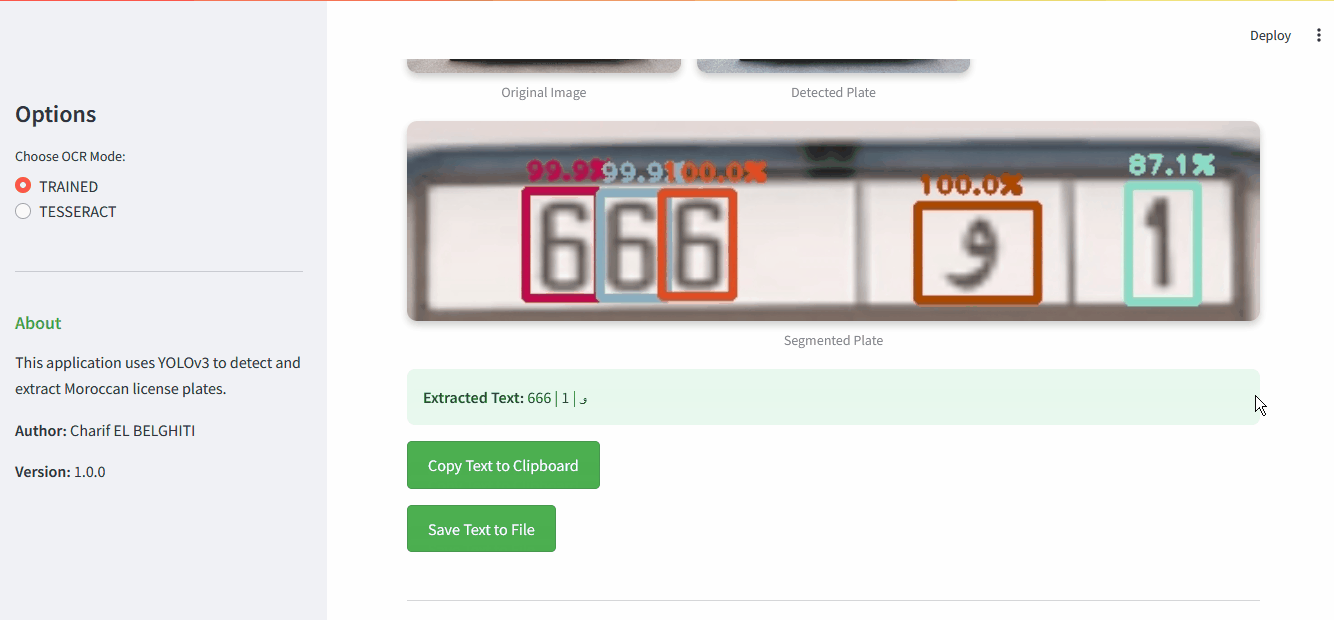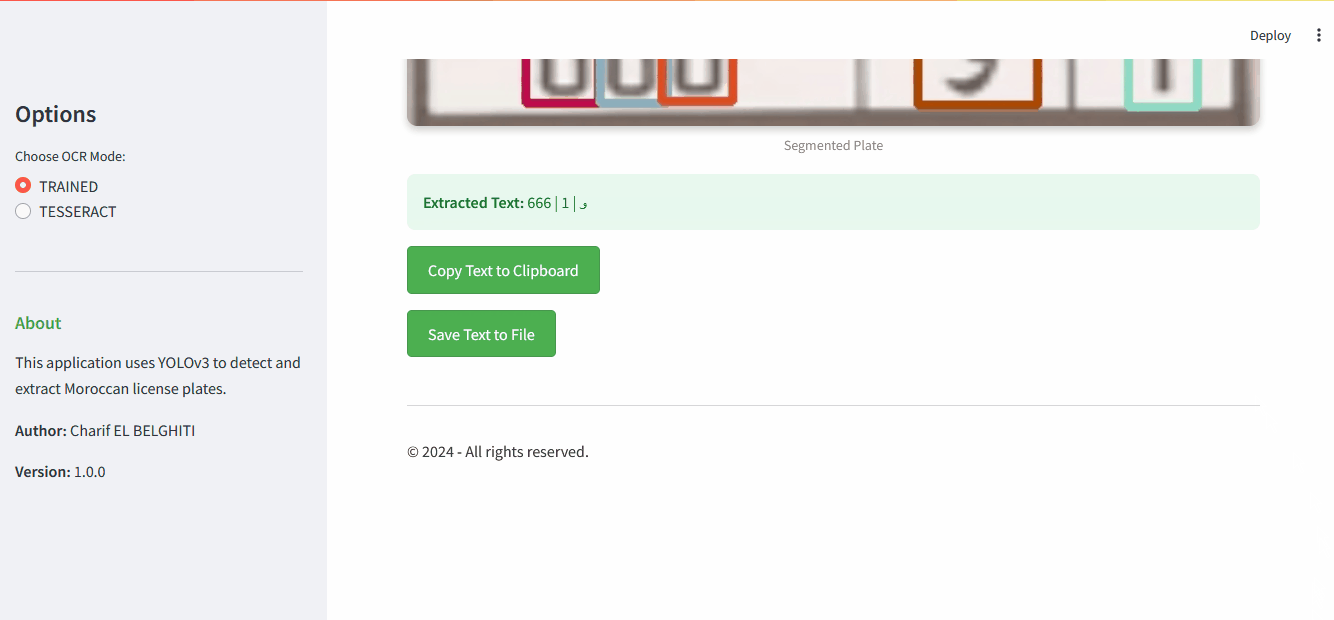 Results page showing detection and recognition steps
Results page showing detection and recognition steps
Conclusion
This project provides a robust solution for detecting and recognizing Moroccan license plates using advanced deep learning and OCR techniques. The combination of YOLOv3 for detection and OCR models for character recognition ensures high accuracy in real-world scenarios.